Graphify для Claude Code и OpenClaw: реальный тест на 78 файлах
Graphify — это новый open source skill для Claude Code и OpenClaw, который превращает любую папку (код, документы, PDF, картинки) в навигируемый граф знаний с кластеризацией и интерактивным HTML. Установка в одну команду, запуск через /graphify внутри агента, никаких векторных баз и конфигов. Я поставил его, прогнал на собственном архиве из 78 markdown-заметок и в этой статье делюсь честным разбором: что реально работает, что приукрашено, и зачем это нужно конкретно тебе.
⚡ Что это вообще такое
Идея пришла из workflow Андрея Карпатого: бросаешь в папку /raw всё подряд — статьи, твиты, скриншоты, заметки, код — и получаешь структурированный граф, который показывает связи, о которых ты сам не догадывался. Карпати написал об этом 5 апреля 2026, а через двое суток на GitHub появился safishamsi/graphify и сразу собрал 2 тысячи звёзд.
Что делает graphify такого, чего сам Claude или OpenClaw не делает:
- 🧠 Постоянный граф. Связи между сущностями сохраняются в
graphify-out/graph.jsonи переживают сессию. Можно вернуться через две недели и задавать вопросы без переписывания всех файлов. - 📋 Честный аудит. Каждая связь помечается как
EXTRACTED(явно в источнике),INFERRED(логичный вывод) илиAMBIGUOUS(под вопросом). Сразу видно, что найдено, а что выдумано. - 🔍 Кросс-документные сюрпризы. Алгоритм community detection находит связи между концептами в разных файлах, о которых ты бы сам не подумал спросить.
🛠️ Установка за минуту
Самый быстрый путь — через pipx (нужен Python 3.10+):
pipx install graphifyy
graphify installВнимание: пакет на PyPI пока называется graphifyy с двумя «y» — авторы временно держат это имя, пока перезахватывают graphify. CLI после установки всё равно зовётся graphify.
Команда graphify install копирует skill в ~/.claude/skills/graphify/ и добавляет нужный блок в CLAUDE.md. Для OpenClaw используй флаг: graphify install --platform claw.
После этого в любом проекте набираешь /graphify . — и пайплайн запускается на текущей папке. Поддержка форматов:
- 💻 Код: 13 языков через AST (Python, TypeScript, Go, Rust, Java и др.)
- 📄 Документы: Markdown, txt
- 📚 Научные статьи: PDF
- 🖼️ Картинки: через Claude Vision (UI-скриншоты, диаграммы, графики, рукописные доски)
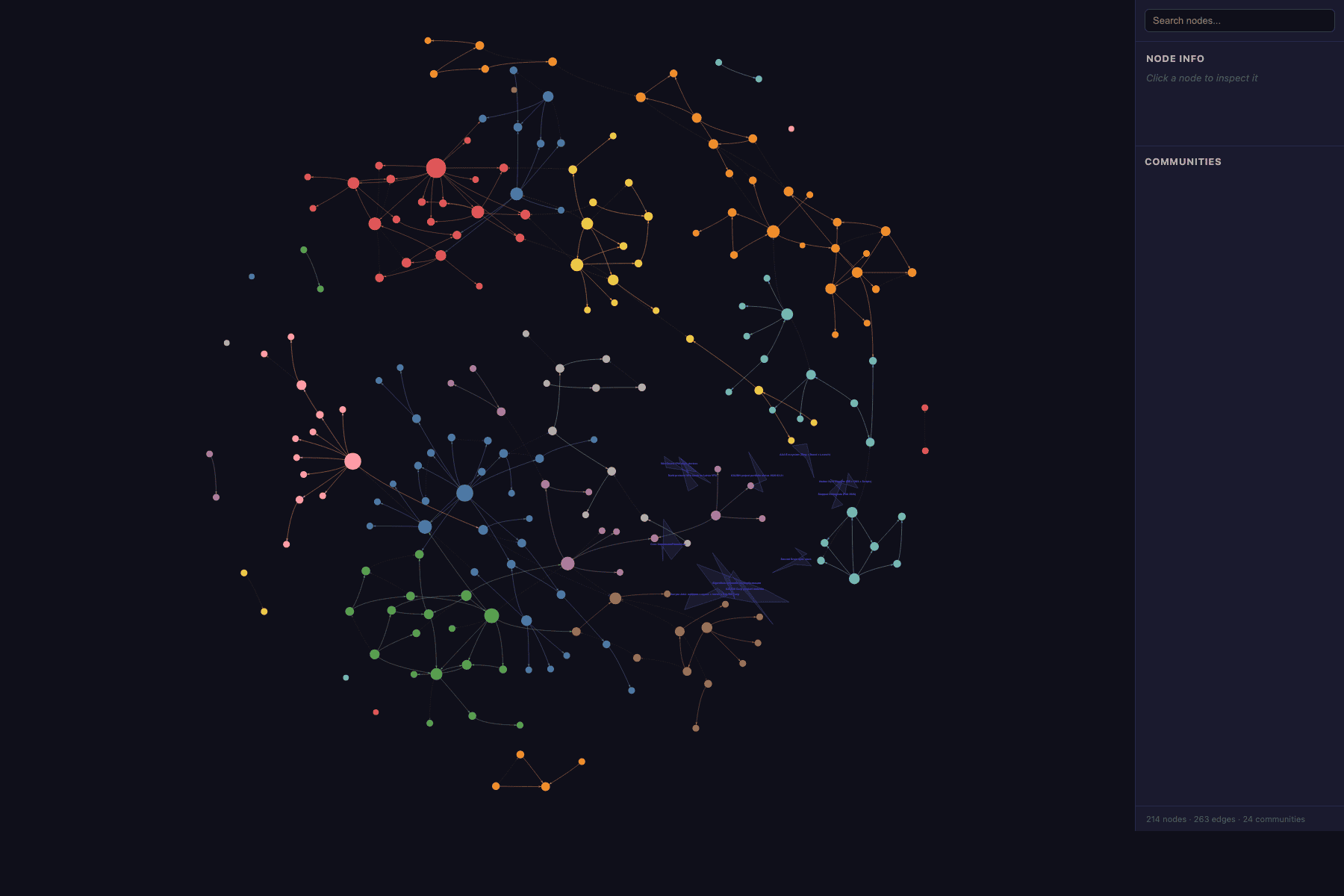
📊 Реальный тест: 78 заметок → граф из 217 узлов
Чтобы не пересказывать README, я скормил graphify свой реальный архив: 78 markdown-файлов с ежедневными заметками за два месяца. Это смешанный контент — дневник, идеи проектов, технические записи по OpenClaw, наброски постов, инфраструктурные решения. Около 26 тысяч слов в сумме.

Что вышло на выходе:
- 📦 214 узлов (концептов и сущностей)
- 🔗 263 связи (плюс 12 гиперсвязей для групп из 3+ узлов)
- 🎨 24 кластера, выделенных автоматически по плотности связей
- ⏱️ ~4 минуты от запуска до готового HTML
Топ кластеров после анализа:
| Кластер | Узлов | О чём |
|---|---|---|
| База знаний и subagent-ы | 26 | Notion, скрипты синхронизации, агентский стек |
| Инфраструктура и приватность | 22 | VPS, WireGuard, AmneziaWG, Mac mini |
| Контентный пайплайн | 20 | Brave → Sonar → Claude → Gemini → Ghost |
| OpenClaw Fixer | 18 | сервис починки агентов и связанные продукты |
| Продуктовые решения | 17 | когорты обучения, стиль постов, паузы инициатив |
Самое интересное — это не сами цифры, а то, что кластеры совпали с реальной структурой работы. Не по датам, не по тегам, а именно по смыслу. Инструмент сам нашёл, что «инфраструктура» и «контент» — это разные ветки, хотя я об этом нигде явно не писал.
🎯 Что работает, а что приукрашено
Реклама обещает «71.5x меньше токенов на запрос». Звучит как маркетинговая дичь, но я залез в исходники: цифра честная, только она про запросы к готовому графу, а не про его построение. Когда ты строишь граф первый раз — платишь полным объёмом токенов на чтение. Зато потом любой вопрос вида «что связано с X» отрабатывает по BFS-обходу одного кластера, а не перечитыванием всех файлов. Вот тут и появляется десятикратная экономия.
Что реально зашло:
- ✅ Кластеризация работает по смыслу, не по структуре. Файлы не сгруппированы по датам или папкам — а по тому, о чём они на самом деле.
- ✅ Центральные узлы (top by degree) сразу показывают, чем ты на самом деле занимаешься. У меня в топ-3 вышли OpenClaw и Karamazov Bot — и это правда главные проекты последних месяцев.
- ✅ Интерактивный HTML с поиском и деталями по клику работает в любом браузере, без сервера.
- ✅ Аудит-метки
EXTRACTED/INFERRED/AMBIGUOUS— отличная штука. Сразу видно, где модель угадала, а где сделала натяжку.
Что приукрашено или ограничено:
- ⚠️ Пайплайн жёстко завязан на параллельные subagent-ы внутри Claude Code. Без них работать не будет — это не standalone-утилита.
- ⚠️ Дубликаты узлов. Разные subagent-ы могут дать одной сущности слегка разные id (например
OpenClawиOpenClaw_framework). Лечится повторным прогоном с флагом--update, но из коробки не дедуплицирует. - ⚠️ Чистый код-режим (только AST) пока не такой мощный — для real value нужны и доки, и код вместе.
🚀 Когда это реально нужно
Это не «давайте поставим всем». Graphify заходит в трёх ситуациях:
- 📦 Большой архив записей. Если у тебя за полгода накопилось 50+ заметок и ты уже не помнишь, что с чем связано — это твой кейс. У меня сработало именно так.
- 🧩 Незнакомая кодовая база. Прогнать на чужом репозитории, чтобы за минуты понять архитектуру и найти центральные модули, не читая каждый файл.
- 📚 Reading list по теме. Сложить статьи + твиты + скриншоты + свои заметки в одну папку и получить связанную карту области.
Для проекта из 5 файлов смысла нет — обычное чтение быстрее. И для красивых демо «смотрите какой граф» тоже не стоит. Это рабочий инструмент, не игрушка.
📂 Что смотреть на GitHub у Graphify перед установкой
Запросы вроде graphify github обычно означают простую вещь: человек хочет понять, живой ли проект, а не просто увидеть красивый README. И это разумно. У Graphify GitHub-репозиторий полезен не только как кнопка «Install», а как способ быстро оценить зрелость инструмента.
На что смотреть в репозитории в первую очередь:
- ⭐ README и supported platforms. Если нужен именно Claude Code или OpenClaw, важно проверить, что они перечислены как поддерживаемые сценарии, а не упомянуты вскользь где-то в issue.
- 🧩 Структуру output. Репозиторий сразу показывает, что ты получаешь не абстрактную «магическую память», а конкретные артефакты:
graph.html,graph.json,GRAPH_REPORT.mdи кэш для повторных прогонов. - 🛠️ Список ограничений. По GitHub видно, что проект лучше всего раскрывается на смешанном корпусе: код + документация + заметки. Если ждать чудес от одной папки со случайными файлами, потом будет больно и немного стыдно.
- 🔁 Историю обновлений. Если в репозитории двигаются коммиты и обсуждения, значит инструмент не заброшен и авторы реально допиливают сценарии вокруг skill-based workflow.
Короче: запрос graphify github — это не просто навигационный мусор. Это нормальный интент человека, который хочет понять, ставить ли инструмент в рабочий стек. И GitHub здесь действительно отвечает на главный вопрос: перед вами живой skill для реальных агентных сценариев или очередная демка на один уикенд.
🧪 Graphify для Claude Code и OpenClaw: где он раскрывается лучше всего
Если смотреть на практику, Graphify сильнее всего там, где агент уже умеет ходить по файлам, делить работу на несколько проходов и возвращаться к результату позже. Поэтому связка Graphify + Claude Code особенно удобна для анализа репозиториев, а Graphify + OpenClaw — для долгоживущих знаний, заметок и внутренних баз.
- 💻 В Claude Code Graphify хорошо подходит для быстрого входа в незнакомый код: поднял граф, увидел центральные модули, связи, причины архитектурных решений — и уже потом идёшь читать конкретные файлы, а не блуждаешь наощупь.
- 🦞 В OpenClaw инструмент полезен, когда нужно скрестить заметки, документацию, daily-файлы, PDF и артефакты проекта в один объяснимый граф. Это уже ближе к «памяти с костями», а не просто к поиску похожих абзацев.
Практический вывод простой: если твой запрос звучит как graphify для Claude Code, то тебе нужен разбор codebase и ускорение навигации. Если запрос ближе к graphify openclaw, то ценность в постоянном графе знаний, который можно дополнять и переиспользовать между сессиями. В обоих случаях штука полезная, но магии нет: лучший результат получается, когда у тебя уже есть внятный корпус файлов, а не цифровой чулан без структуры.
❓ FAQ
Сколько токенов уходит на построение графа?
Зависит от объёма. На моих 78 файлах (26 тысяч слов) ушло около 170 тысяч токенов в сумме на четыре параллельных subagent-а. Дальше каждый запрос к графу обходится в районе 1500–3000 токенов вместо чтения всего корпуса.
Нужна ли векторная база (Pinecone, Chroma, Qdrant)?
Нет. Graphify использует именно граф, а не эмбеддинги. Это другой подход с другими сильными сторонами: он лучше для структурных и причинных связей, хуже для нечёткого семантического поиска.
Поддерживает ли OpenClaw?
Да, из коробки. Команда установки: graphify install --platform claw. Skill автоматически подцепляется к OpenClaw-сессии и команда /graphify работает так же, как в Claude Code.
Можно ли запускать инкрементально, не перестраивая всё?
Да, флаг --update переиндексирует только изменённые и новые файлы. Подходит для постоянного добавления новых заметок в одну папку.
Что с приватностью? Файлы куда-то уходят?
Содержимое уходит в Claude (через subagent-ов), как и при обычном использовании Claude Code. Локально на диск пишется только результат — JSON и HTML. Файлы с пометкой sensitive (например .env, ключи) автоматически пропускаются на этапе detection.
В чём разница с обычным RAG?
RAG ищет похожие куски текста по векторам. Graphify строит явный граф сущностей и связей, и при запросе обходит этот граф. Для вопросов «что связано с X», «что между X и Y» graph-подход даёт более структурный и объяснимый ответ. Для свободного семантического поиска — RAG всё ещё сильнее.
Какие выходные форматы?
Из коробки: интерактивный HTML, JSON для GraphRAG, Markdown-отчёт. Опционально: SVG (для встраивания в Notion и GitHub), GraphML (Gephi, yEd), Cypher для Neo4j, MCP-сервер для прямого подключения других агентов.
Почему люди ищут именно graphify github, а не просто graphify?
Потому что для новых open source-инструментов GitHub — главный маркер живости проекта. По репозиторию видно поддерживаемые платформы, формат выходных файлов, ограничения и активность авторов. Для Graphify это особенно важно, потому что инструмент завязан на реальный workflow, а не на красивый лендинг.
Graphify и graphifyy — это одно и то же или нет?
Сейчас да: пакет в PyPI называется graphifyy, а сам CLI и GitHub-репозиторий — graphify. Это временная техническая история с именем пакета, а не другой продукт. Если ставите через pipx и потом запускаете команду graphify, всё нормально.
Когда Graphify лучше обычного grep, tree и RAG?
Когда нужно увидеть связи между сущностями, кластеры тем и архитектурные причины, а не просто найти совпадение строки. Для точечного поиска по коду grep быстрее. Для размытого семантического поиска RAG часто сильнее. А вот для вопросов «что связано с этим модулем», «какие темы сходятся вокруг этой сущности» и «почему эти документы тянут друг друга в один кластер» Graphify выигрывает.
Если хочешь следить за такими разборами по AI-агентам, OpenClaw и автоматизации — подписывайся на канал @aaakalsin. Там я выкладываю всё, что реально тестирую, без хайпа и маркетинговой ваты.